Alguns desenvolvedores dão somente muita atenção à codificação. Vejamos outros importantes aspectos...
Confira neste artigo as diferenças de alguns cargos da área de TI.
Em meio ao desenvolvimento de software, você pode ter visto em algum momento a sigla “MVC”. Confira...
Aprenda a criar uma estrutura de pastas e arquivos com React para ter uma aplicação com fácil manute...
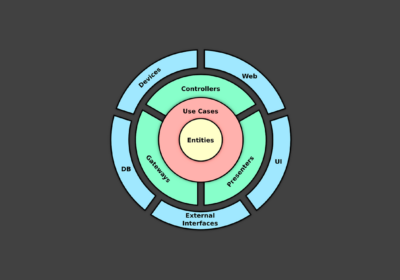
Confira nesse artigo uma introdução do que é a Clean Architecture, quais seus componentes e os benef...
Veja neste artigo o que é Ember.js.
Veja neste artigo boas práticas que você deve ter com seu código.
Veremos neste artigo o que é o CodeIgniter, um dos principais frameworks PHP do mercado, e suas prin...
Qual o motivo por trás do surgimento de tantas ferramentas em forma de serviço? Quais as principais...
Neste primeiro artigo da série sobre SOLID, vamos entender o porquê de eles terem sido definidos, al...
Confira neste artigo uma breve introdução ao DDD: o que é domínio, linguagem úbiqua e bounded contex...
Confira neste artigo quais são as etapas do Ciclo de Vida de Testes de Software e entenda sua import...
Design Patterns (Padrões de Projeto) são soluções para problemas comuns que encontramos no desenvolv...
Confira nesse artigo um breve overview da Lei de Conway e como ela afeta a forma que os softwares sã...
Quando falamos de Software as a Service (SaaS) e cloud computing, é inevitável que o termo "multiten...
Confira neste artigo o que vem a ser programação reativa, um princípio de desenvolvimento de softwar...
Nesse artigo uma introdução à arquitetura Serverless e um pouco sobre o AWS Lambda, um dos principai...
Conheça neste artigo o que é o MEAN Stack.
Veja neste artigo o que vem a ser o ALM (Application Lifecycle Management).
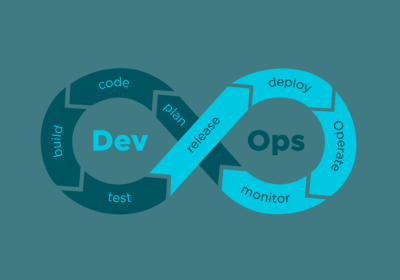
Você sabe o que é DevOps? Confira neste artigo.