Qual linguagem escolher? Java, C# ou PHP? Quais são as vantagens de cada uma? Vamos analisar estas d...
Aprenda como trabalhar com classes, atributos, métodos e objetos no C# e aumente seus conhecimentos...
Nesse guia de C# você aprenderá o necessário para criar os seus primeiros softwares com a linguagem...
Conheça o Pattern Matching adicionado na versão 7.0 do C#.
Conheça um pouco mais sobre o recurso Ref Returns da versão 7 do C#.
Aprenda o que são e como funcionarão as tuplas no C# 7.
Veremos nesse artigo sobre quais são e como podemos utilizar as estruturas condicionais e as estrutu...
Conheça neste artigo os tipos de dados presentes no C# e a sintaxe para que possamos declarar variáv...
Aprenda a criar um tipo que pode ser retornado pelos métodos assíncronos do C#.
Veja como o Cake pode auxiliar na automação de tarefas de um projeto .NET Core.
Conheça as mudanças de Expression-bodied members no C# 7.
Conheça os recursos Binary Literals, Digit Separators e Throw Expressions da versão 7 do C#.
Veja um exemplo de como se conectar ao MySQL no Entity Framework Core.
OData é um padrão de boas práticas para a criação de API. Veja os recursos que este padrão fornece p...
Conheça a biblioteca AutoMapper e aprenda como implementá-la em uma aplicação C#.
Testes unitários ajudam a garantir a qualidade de uma aplicação. Uma forma de garantir isso no C# é...
Verificar e monitorar a integridade de uma aplicação web é algo essencial, principalmente em ambient...
Você já quis criar tarefas em segundo plano com o .NET Core? Na versão 3.0 foi introduzido o templat...
Aprenda quando utilizar os métodos AddMvc(), AddMvcCore(), AddControllers(), AddControllersWithViews...
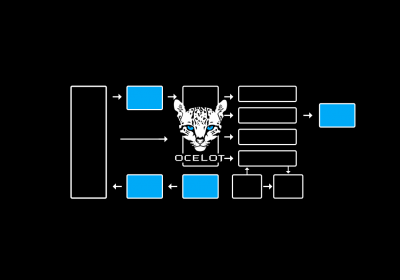
Conheça o conceito de API Gateway e veja como criá-lo em uma aplicação ASP.NET utilizando a bibliote...