Neste artigo veremos o que é o VS Code e como podemos realizar a sua instalação nos sistemas operaci...
Neste artigo veremos como instalar o Java nos sistemas Windows, Linux e MacOS, além disso vamos ver...
Veja um pouco mais sobre os sistemas de codificação de caracteres ASCII e Unicode.
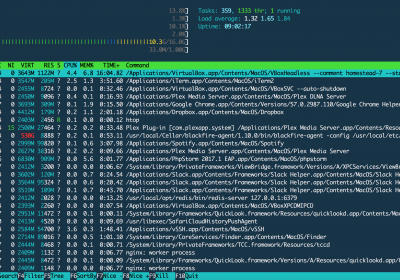
O htop é uma ferramenta multiplataforma, visual e interativa, para visualizar processos e recursos e...
Nesse artigo vamos aprender o que é o Windows Subsystem for Linux (WSL), quais as suas funcionalidad...
Veja neste artigo as vantagens de se estudar o Flutter.
Quer iniciar seus estudos em Java e não sabe por onde começar? Veja o que preparamos pra você.
Veja as configurações necessárias para utilizar o MySQL em uma aplicação C.
Concorrência, paralelismo, processos, threads, programação síncrona e assíncrona, são assuntos que p...
Você, desenvolvedor PHP, já teve a oportunidade de trabalhar mais intimamente com Streams? Se você j...
Veja neste artigo o que é o Ionic, principal Framework para desenvolvimento de aplicações móveis híb...
Neste artigo veremos como criar uma máquina virtual utilizando a VirtualBox com o sistema operaciona...
Neste artigo veremos alguns editores de código para utilizar na criação de seus projetos.
Neste artigo veremos o que é Git e seus principais comandos.
Aplicações Desktop ainda são muito utilizadas. Neste artigo aprenda como utilizar o GTK para criar i...
Nesta série de artigos sobre termos comuns de segurança, conheça o honeypot, uma armadilha destinada...
Veja neste artigo como dar os primeiros passos utilizando o MySQL.
Neste artigo sobre Introdução ao gerenciamento de projetos Node.js vamos aprender os principais coma...
Nesse guia da linguagem Dart você aprenderá o necessário para criar os seus primeiros softwares com...
Veja como configurar o GTK no Code::Blocks e passe a utilizar esta IDE para criar seus projetos em C...