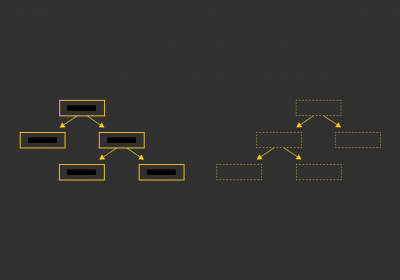
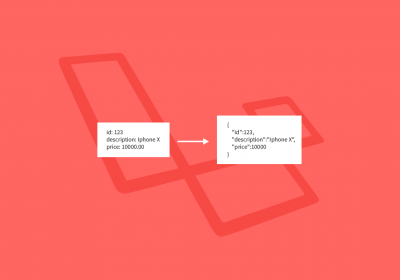
Agora que já sabemos o que é o XML e o JSON, qual escolher? É o que veremos neste artigo.
Veja neste artigo o que é XML e suas principais características.
No Android é possível modificar a aparência de um botão (tamanho, cor, borda, alinhamento etc) via X...
A Fetch API veio para substituir a antiga XmlHttpRequest e o suporte dela já é bem consistente nos n...
Ao utilizar JavaScript para desenvolvimento web, é necessário entender o funcionamento do DOM (Docum...
JSON Schema é uma especificação para validação de documentos JSON. A ideia é parecida com a de um XS...
Veja neste artigo o que é e para que serve o YAML.
Veja neste artigo o que é XSLT.
Neste artigo veremos o que é o Spring Boot e como ele pode nos auxiliar no desenvolvimento de aplica...
Otimize seu desenvolvimento Java! Descubra como o WebJars simplifica o gerenciamento de dependências...
Hoje, é relativamente comum estarmos em contato com requisições AJAX. Confira neste artigo como essa...
Entenda o que realmente é o DOM e sua diferença em relação ao Virtual DOM e Shadow DOM.
Um dos pontos mais importantes quando estamos trabalhando APIs é o retorno dos dados. Veja como melh...
O LINQ é uma das features mais legais e poderosas do .NET. Porém, você sabe exatamente o que é o LIN...
Nesse artigo falaremos um pouco sobre o que é serialização de dados e quais os principais recursos q...
Quer iniciar seus estudos em PHP e não sabe por onde começar? Veja o que preparamos pra você.
Muitas pessoas acreditam que JSON e Objeto JavaScript são a mesma coisa. Descubra a diferença.
Saiba o que é o gerenciador de pacotes Dart e Flutter, como utilizar um pacote, biblioteca instalada...
Veja como podemos utilizar o projeto Lombok para diminuir a quantidade de código boilerplate e acele...
Aprenda como instalar e configurar o ambiente de desenvolvimento PHP Laravel no Linux.