Você sabe o que vem a ser o Kubernetes e como ele pode nos ajudar? Confira neste artigo.
Conheça mais sobre o OpenShift e como ele funciona.
Existem alguns aspectos técnicos e comportamentais que podem te ajudar a seguir para o próximo nível...
Confira neste artigo o que vem a ser um container.
Você já ouviu falar no Laminas? Para quem não sabe, esse é o novo nome do já conhecido Zend Framewor...
Com o lançamento do WSL 2, agora é possível executar o Docker sem precisar de uma máquina virtual tr...
Confira neste artigo alguns motivos que nos mostram o porquê de valer a pena aventurar-se nessa área...
Confira neste artigo quais são as tendências de tecnologia para este ano.
Nesta terceira parte, iremos abordar mais três dos 12 princípios: port binding, concurrency e dispos...
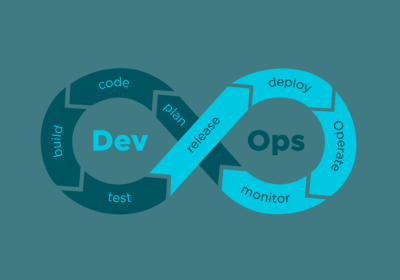
Você sabe o que é DevOps? Confira neste artigo.