Implemente testes unitários em requisições HTTP com o auxílio de Flurl.
Veja como consumir dados de uma API no C#, utilizando a biblioteca Flurl.
Conheça os novos tipos de dados introduzidos no C# 9.0, os inteiros nativos e os novos recursos da i...
Dando continuidade ao nosso estudo do C# 9.0, neste artigo veremos dois novos recursos dele: Program...
Já estamos no C# 9.0, a nova versão lançada no .NET Conf 2020 trouxe uma série de novos recursos, ve...
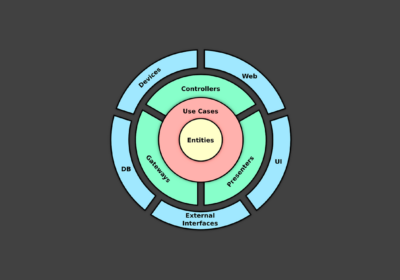
Confira nesse artigo uma introdução do que é a Clean Architecture, quais seus componentes e os benef...
Como trabalhar com data e hora no Python com Datetime. No decorrer deste artigo, veremos exemplos de...
Neste artigo iremos aprender como instalar a Golang nos sistemas Windows, Linux e macOS e como execu...
Carreira mobile tem muitas oportunidades, por isso vamos ver o que você precisa saber para entrar ou...
Conheça neste artigo os tipos de dados presentes no C# e a sintaxe para que possamos declarar variáv...
Neste artigo veremos como instalar o C# nos sistemas Windows, Linux e MacOS e também veremos como es...
Neste artigo vamos aprender como criar uma API com persistência de dados utilizando o Spring Web MVC...
Aprenda como instalar e configurar o ambiente de desenvolvimento Spring Boot no Windows
Neste artigo conheceremos o Gerenciador de Pacotes Homebrew.
Neste artigo conheceremos as variáveis e constantes no Dart.
Conheça mais uma lista de extensões do VS Code que ajudarão a melhorar a sua produtividade e facilit...
Veja como configurar o GTK no Code::Blocks e passe a utilizar esta IDE para criar seus projetos em C...
Aplicações Desktop ainda são muito utilizadas. Neste artigo aprenda como utilizar o GTK para criar i...
Neste artigo veremos como instalar o Dart nos sistemas Windows, Linux e MacOS e executar nosso prime...
Conheça neste artigo as variáveis, tipos de dados e constantes da linguagem Java.