Fazer uma transição de carreira pode ser muito desafiador e com muitas incertezas. Confira essas dic...
Neste artigo vamos aprender a utilizar os eventos com o NestJS, criando um exemplo onde vamos simula...
Confira nesse artigo algumas dicas para que você não tenha uma sobrecarga de informações e consiga e...
Otimize seu desenvolvimento Java! Descubra como o WebJars simplifica o gerenciamento de dependências...
Confira nesse artigo algumas dicas para tirar o máximo de proveito e maximizar o seu aprendizado em...
Neste artigo vamos ter uma introdução sobre o Zod, uma biblioteca de declaração e validação de dados...
Confira neste artigo dicas valiosas para você administrar sua carreira e obter sucesso.
Domine modais em HTML com a tag 'dialog'. Crie, personalize e interaja em seu site. Torne-o envolven...
Confira nesse artigo um breve overview da Lei de Conway e como ela afeta a forma que os softwares sã...
Descubra o poder das Scheduled Tasks no Spring Boot. Aprenda a criar, configurar e aprimorar tarefas...
Desvende os segredos dos arrays em JavaScript! Aprenda métodos poderosos para manipulação eficiente....
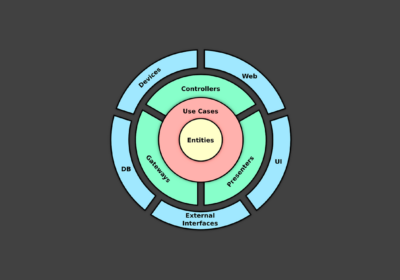
Confira nesse artigo uma introdução do que é a Clean Architecture, quais seus componentes e os benef...
Neste artigo vamos utilizar o módulo nativo scheduler do NestJS para trabalhar com tarefas automatiz...
Domine a programação assíncrona com CompletableFuture no Java e impulsione o desempenho de sua aplic...
Veremos nesse artigo algumas estratégias que você pode aplicar, se tornando mais confiante para alca...
Nesse artigo aprenderemos a criar uma máscara para inputs que irá deixar seus projetos mais profissi...
Professor especialista em Desenvolvimento Front-end na TreinaWeb. Akira, Felipe, Hana, Hanashiro ou Hanakira, é graduado em Análise e Desenvolvimento de Sistemas, pós-graduado em Projetos e Desenvolvimento de Aplicações Web e MBA em Machine Learning, é entusiasta no desenvolvimento de jogos e multi-task. Fala japonês fluente, mas não tem com quem conversar.
Coordenador e instrutor na TreinaWeb. Elton é graduado em Análise e Desenvolvimento de Sistemas e pós-graduado em Arquitetura e Engenharia de Software. Apaixonado por desenvolvimento de software e tudo ligado à área de tecnologia. Atua em diversas áreas, como desenvolvimento Back-end, Full Stack e Cloud Computing.
Professor, programador, fã de One Piece e finge saber cozinhar. Cleyson é graduando em Licenciatura em Informática pelo IFPI - Campus Teresina Zona Sul, nos anos de 2019 e 2020 esteve envolvido em vários projetos coordenados pela secretaria municipal de educação da cidade de Teresina, onde o foco era introduzir alunos da rede pública no mundo da programação e robótica. Hoje é instrutor dos cursos de Spring na TreinaWeb, mas diz que seu coração sempre pertencerá ao Python.
Professor na TreinaWeb e graduado em Sistemas de Informação pelo Instituto Federal da Bahia. Apaixonado por desenvolvimento web, desktop e mobile desde os 12 anos de idade. Já utilizou todos os sistemas operacionais possíveis, mas hoje se contenta com o OSX instalado em seu notebook Samsung =/. Até passou em uma peneira do Cruzeiro, mas preferiu estudar Python.
Formado em Automação e controle de processos, trabalha com redes de computadores desde 2007 e possui a certificação CWTS (Certified Wireless Specialist). Largou a automação industrial e atualmente trabalha com virtualização, segurança da informação, redes, IoT, cloud e desenvolvimento .NET para desktop e mobile.
Graduado em Sistemas de Informação e Pós-graduado em Redes de Computadores e Segurança de Sistemas. Atualmente exerce a função de administrador de redes em uma instituição de ensino superior e também ministra aulas de tecnologia da informação na Etec de Bebedouro. Tem sua empresa onde presta consultorias na área de redes, segurança e infraestrutura, e também ministra cursos online.
Professor dos cursos de UX, Acessibilidade e demais cursos relacionados à experiência de usuário, Wilson (mais conhecido por Bizon) é focado criar soluções que possam fazer a diferença. Também é Professor no curso de Pós-graduação em UX e Arquitetura da Informação da Impacta e único Axure Approved Trainer da América Latina. Além de ter o sobrenome de um personagem do Street Fighter e ser um vocalista sem banda, também já atuou com desenvolvimento Front-End e Animação.
Formado em Análise e Desenvolvimento de Sistemas pelo Instituto Federal de São Paulo, atuou em projetos como desenvolvedor Front-End. Nas horas vagas grava Podcast e arrisca uns três acordes no violão.
Professor, Desenvolvedor e Gerente de Projetos na Treinaweb. Wlad é nerd, cinéfilo e desenvolvedor nas horas vagas. Graduado em Ciências da Computação pela Universidade Metodista de São Paulo, ele lê em média um livro por semana e nem por isso é muito antissocial. Tem TOC, mas nega.
Felipe Oliveira atua como Agile Coach na WebMotors, fundador e Agile Expert na Mindset Ágil - Consultoria e Treinamentos, instrutor credenciado para as certificações PRINCE2 Agile Foundation e Lean IT Foundation, voluntário do PMI, professor convidado da FAAP de Sâo José dos Campos, instrutor de gestão da TreinaWeb. È especialista em gestão de projeto pela FGV e possui mais de 15 certificações de gestão, entre elas PSM I, PSPO I, PRINCE2 Agile Practitioner, PRINCE2 Foundation, LITAF, entre outras.
Professor especialista em cloud computing na TreinaWeb. Graduado em Gestão de TI pela FATEC e quase bacharel em Sistemas de Informação pela UFSCar. Tem experiência em desenvolvimento backend com PHP, mas se encontrou trabalhando com DevOps. Possui mais de uma dúzia de certificações na área de TI e nas horas vagas gosta de maratonar séries na Netflix, jogar CS:GO e poker.
Professor de cursos relacionados à gestão de projetos. Possui mestrado em Administração Estratégica e com ampla experiência em gerenciamento de portfólio de projetos de alta complexidade em empresas de vários segmentos como TI, Telecom, Indústrias, Finanças e Energia. Atua como professor de turmas de Pós graduação e MBA e possui mais de 40 certificações internacionais de TI. Além disso, é autor de vários livros sobre gerenciamento de projetos, gestão de serviços de TI e sobre Redes de Computadores.
Cleber é pós-graduado em Projeto e Desenvolvimento de Aplicações Web, além de Microsoft Specialist (HTML5/CSS3), Microsoft Certified Solutions Associate (MCSA) Web Applications e Microsoft Certified Solutions Developer (MCSD) Web Applications. Fascinado por Arquitetura de Software, Programação Funcional, Machine Learning e educação em geral. Também é conhecido como "o boladão".
Responsável pelo sucesso do cliente na TreinaWeb. Marylene é graduada em Gestão de Tecnologia da Informação pela FATEC Guaratinguetá, além de estudante de Marketing Digital e Mídias Sociais. Noveleira de carteirinha, nas horas vagas também acumula outras funções, como revisão de cursos e redação de artigos. Tudo isso lá de cima, do alto dos seus 1,50m.
Graduanda em Sistemas de Informação pelo Instituto Federal da Bahia. É responsável pelo atendimento ao cliente, gerenciamento de redes sociais e revisão de cursos, além da redação de artigos para o blog da TreinaWeb. Nas horas vagas, enquanto seu marido joga CSGO, dedica seu tempo a cuidar do Arnaldo, um pinscher sedentário que a impediu de manter uma vida fitness e sociável.
Professor líder e Coordenador dos cursos de audiovisual do AvMakers. Bruno, ou simplesmente Balta, trabalha com pós produção há mais de 18 anos. É Authorized Trainer DaVinci Resolve, Adobe Certified Instructor em After Effects, Premiere Pro, Illustrator, Lightroom, Photoshop, e ainda Video Specialist. Também conhecido como o "manual ambulante da Adobe". Trabalha como colorista tendo atuado em dezenas de filmes de séries.
Designer Web/Gráfico e Gerente de Mídias Sociais na TreinaWeb. Felipe é graduado em Publicidade, Propaganda e Criação pela Universidade Mackenzie de São Paulo, e especialista em Branding. Já desenvolveu mais de 200 logos aprovadas por seus clientes, mas o que ele queria mesmo era ser jogador de futebol profissional. (in)Felizmente, não passou na peneira e se contentou com várzea.
Fotógrafa e Videomaker no AvMakers. Fernanda é graduada em Publicidade e Propaganda e pós-graduada em Comunicação Audiovisual pela PUC PR. Trabalha com produção audiovisual desde 2007, entre produções publicitárias, institucionais, EAD e Making Of para cinema, videoclipe e demais projetos audiovisuais. Isso tudo quando não está cuidando do Gael ou correndo atrás do Astolfo.
Cinegrafista, fotógrafo e documentarista de natureza e vida selvagem com base na Grande Reserva Mata Atlântica. Formado em Comunicação Social - Jornalismo pelo Grupo Educacional UNINTER e especialista em Produção e Mercado Audiovisual pela PUC PR.
Produz e dirige filmes com a temática da Conservação da Natureza e Vida Selvagem para diversas instituições do terceiro setor, como a SPVS, Associação MarBrasil, Instituto Meros do Brasil e diversos projetos apoiados pela Fundação Grupo Boticário, FunBio, Petrobras SocioAmbiental, ITAIPU Binacional e BNDES.
Diretor da série “Histórias da Grande Reserva Mata Atlântica” (2018-2020), com 3 episódios produzidos. Diretor do documentário “Sentinelas do Mar” (2019) e Diretor do curta-metragem “O Bicudinho-do-brejo” (2022) exibido na amostra do Festival de Cinema Mata Atlântica EcoFestival.
Professor, coordenador e produtor de conteúdo no AvMakers. Rafael é formado em Comunicação, graduando em Cinema e Audiovisual e mestre em Cinema e Artes do Vídeo pela Faculdade de Artes do Paraná. Já foi redator em assessoria de comunicação e agência de publicidade, mas encontrou na produção e pesquisa cinematográfica sua verdadeira paixão. É tão estudioso da área que não sobra tempo de ir ao cinema para ver os lançamentos, mas ele se contenta com filmes de 1920.
Formado em fotografia profissional e documental, Rodolfo Massambone entrou para o mundo das imagens em 2010. Desde então desenvolve projetos comerciais e autorais na área da fotografia onde também dá aulas à nível básico, médio e avançado. Hoje sua principal atividade é como Fotógrafo e Professor de fotografia.
Fernando Hideki é Diretor de Videoclipes, Diretor de Fotografia, Editor, Colorista, Piloto de Drone e Músico. Sua principal característica é a movimentação livre de câmera, deixando suas imagens ainda mais vivas. Já trabalhou com diversos artistas de nível nacional, seus trabalhos de videoclipes somam mais de 5 milhões de visualizações no YouTube. Sempre atrás de novas tendências, procura inserir suas marcas visuais de movimento, simetria, novas técnicas de fotografia e edição para tornar cada vídeo único. "Feeling é tudo".
João Castelo Branco é um premiado Diretor de Fotografia de cinema e televisão, estudou na FAMU - Faculdade de Cinema da Universidade Nacional de Artes de Praga, e INHA – Instituto Nacional de História da Arte, em Paris. Fotografou filmes que estiveram em alguns dos principais festivais de cinema nacionais e internacionais. Recentemente dirigiu a série Contracapa, licenciada para a AXN, e o longa-metragem argentino La Chancha.
Retocador digital e fotógrafo residente em Florianópolis, atuou por mais de 20 anos no setor gráfico como designer, diagramador e arte finalista. Também prestou serviços por 5 anos como fotógrafo de produtos, arquitetura e gastronomia.
Hoje presta serviços para fotógrafos como freelance em tratamento de imagem nas áreas de beleza, moda, fotografia comercial. Além disso atua como fotógrafo especializado em ensaios femininos.
Também atua como instrutor de tratamento de imagem com foco em pele, onde ministra workshops e palestras em congressos os quais se destacam o Photoshop Conference 2017 e Capture Conference 2018.
Fábio Zang é publicitário não praticante e há 6 anos é fotógrafo de Publicidade, Moda, Beauty e Retratos, depois de ter experimentado todas as outras áreas da fotografia. Já foi professor no curso de Produção de Moda para Fotografia no SENAC e atualmente é instrutor de fotografia em plataformas online e workshops presenciais. Atendeu empresas como GMC, Evoóc, Absolutti, XP Investimentos, Cristália Farmacêutica, RCE, Ambev Global Tech, entre outras, e já teve seu trabalho veiculado em grandes revistas de circulação nacional e portais, como Caras, Cabelo & Cia, Exame, G1, Uol, Vogue Itália, e mais alguns. Fábio é também é músico nas horas vagas, e tem um jeito carismático e bem agitado.
Northon Napoleão é Piloto DJI Nível 40 e instrutor RPAS desde 2014. Já ministrou treinamentos na área de pilotagem e aerofotogrametria com multirrotores para instituições públicas, institutos de pesquisa, empresas de engenharia, arquitetura, audiovisual, e também para grandes players do Sul do país e multinacionais, como Klabin, Bosch, Band, BOPE, entre outros, além de customizar projetos de multirrotores long endurance e long range.
Filmmaker e Storyteller, desde criança apaixonado pelo audiovisual. Através de seu trabalho, Eric tem o objetivo de contar histórias cada vez mais significativas, pois considera que elas são a chave para conectar emocionalmente as pessoas de qualquer lugar do mundo.
Fascinado pelo audiovisual desde o início da sua adolescência. Estudou Publicidade e Propaganda
Graduado em Comunicação Social/Cinema pela PUC-Rio, pós-graduado em Linguagens Artísticas, Cultura e Educação pelo IFRJ, e mestrando em Estudos Cinematográficos na Universidade Lusófona, em Portugal. Dogi possui 10 anos de experiência em produção audiovisual, predominantemente como editor de vídeos e diretor. Já editou 2 documentários de longa metragem, diversos programas de TV, além de atuar como editor artístico durante 5 anos nos Canais Globosat.
Rafael é Bacharel em Música pela UFPR. Amante da fotografia desde sempre, iniciou sua carreira pelos caminhos das artes visuais em 2011, fotografando casamentos e artistas. Logo começou seus primeiros trabalhos com videoclipes, que hoje é sua principal atividade, atendendo diversos artistas do Brasil inteiro, dos mais diversos estilos musicais.
Professor de áudio no AvMakers, Airton iniciou os estudos de música aos 6 anos de idade. É formado pelo “Conservatório Musical Souza Lima” no Curso Dinâmico de Áudio e Bacharelado em Audiovisual pelo Senac. Como violonista já se apresentou em programas como o “Encontro com Fátima Bernardes” e do TEDx, além de canais do youtube de grande reconhecimento. Como produtor musical, operador de som e mixagem, atuou com diversos nomes muito importantes do cenário nacional.
Nascido numa sexta-feira 13, André Bales tem como paixão o desenho, seja ilustrando em papel, grafitando ou modelando. Aos 12 anos descobriu o Flash, que o fez desenvolver uma forte paixão por ilustrações e animações, e em pouco tempo já dominava esta e outras ferramentas, como Photoshop, Illustrator, Blender e etc. Aos 19 anos entrou no curso de Design Gráfico da Universidade Positivo, onde passou de um mero ilustrador para projetista gráfico, dando mais profundidade em suas artes. Hoje possui a mescla entre pensar e fazer design, desenvolve artes visuais estáticas, motion graphics, modelagem 3D e ilustração, para identidades visuais e projetos especiais.
William de Oliveira é formado em Produção Audiovisual pelo Instituto Federal do Paraná - IFPR e já escreveu e dirigiu curtas-metragens selecionados para importantes festivais nacionais e internacionais. Seu curta-metragem "Aquele Casal" esteve na 23º Mostra de Tiradentes e no 41º Festival de Havana, entre outros. Ele também é co-roteirista do curta-metragem "Pausa Para o Café", vencedor do Candango de Melhor Roteiro de Curta-Metragem no 53º Festival de Brasília do Cinema Brasileiro.
Analista de Marketing e Growth Hacker na TreinaWeb. Thiago é um grande estudioso sobre negócios digitais e novas tendências do marketing digital. Graduado em jornalismo e em Artes Visuais, também é pós-graduado em Marketing pela FGV. Atua há mais de 10 anos no ramo e é especialista em todas as frentes do marketing digital, como: tráfego pago, SEO, copywriting, inbound marketing e branding.
Gestor de Tráfego e Marketing de Performance na TreinaWeb. Fernando é graduado em Marketing e Propaganda pela UNOPAR de Londrina/PR. Especialista em Marketing Digital, desde 2008, fanático por números e organização, e vasta experiência em mídias pagas, ads, infoprodutos, analises e performance. Apaixonado por música, toca Guitarra, Piano e Canta! Também é um viciado em Jogos Online, ARPG e FPS, como todo bom entusiasta de PC.
Trabalha com desenvolvimento na TreinaWeb. Kennedy é graduado em Sistemas de Informação e tem vasta experiência em desenvolvimento Web com foco em PHP e AWS. Não consegue viver um dia sem instalar o último update da galáxia e por isso já usa tudo em BETA. Se o site sair do ar, a culpa é toda dele! Pode cobrar.
Fundador dos portais de EAD TreinaWeb e AvMakers e co-fundador da FilmeCon, um dos principais encontros técnicos do mercado audiovisual brasileiro. Além disso, é jogador profissional de FIFA (pelo menos acha que é) e se existisse, ocuparia a primeira cadeira no comitê internacional de piadistas ruins.
Graduado em Web Design, Análise e desenvolvimento de sistemas e pós-graduado em Ciência de dados - BigData Analytics. Atua como desenvolvedor Full Cycle, DevOps e DevSecOps e é completamente apaixonado por desenvolvimento web e games.
Estudante de Análise e Desenvolvimento de Sistemas, apaixonado por tecnologia. Atualmente focado na área de front-end e iniciando uma grande e brilhante caminhada tanto profissionalmente quanto pessoalmente nesse universo que é a programação.
Graduado em Ciências e Tecnologia e pós-graduado em Gestão de Projetos de TI, se apaixonou pelo desenvolvimento de software lá na primeira aula de Delphi do curso técnico. Desde então vem trabalhando na área, sempre compartilhando o conhecimento adquirido por meio de cursos, artigos e palestras. No momento atua também como gerente de projetos e Scrum Master.
Professor e desenvolvedor. Formando em engenharia de software. É autor de cursos em diversos temas, como, desenvolvimento front-end, Flutter, JavaScript e Vue.js. Nas horas vagas adora estudar sobre tecnologia, filme e brincar com a pequena Maria Eduarda.
Instrutora front end, cinéfila fã da marvel, star wars e Naruto. Graduanda em Sistemas de informação pelo Instituto federal de Educação Ciência e Tecnologia do estado do Ceará.
Profissional de Tecnologia da Informação Voltado para o Data Science e Instrutor de Cursos Online. Durante alguns anos de docência, busquei ministrar disciplinas a muitos alunos do IFMA, nos últimos meses, meu objetivo tem sido levar conhecimento para outros alunos, por meio da internet, transmitindo os conhecimentos e as experiências que adquiri em minha carreira.
Cursando Desenvolvimento de Sistemas na Escola Técnica Estadual Doutora Ruth Cardoso, atualmente se especializando no Front End com objetivo de se tornar um Full Stack. Nas horas vagas costuma cozinhar, pois é apaixonado pela área da culinária.